If you never worked with Testable before, you can check out our 10-minute introduction video here
The old/new recognition test (ONR) is a simple test where participants need to first memorise a list of items to then decide if words from a new list are old or new. This task relies on recognition memory and contrasts recall memory tests where participants need to reproduce previously learned items.
‘How do we remember’ is a fascinating area of study that has been of interest to psychologists since Hermann Ebbinghaus carried out his famous memory decay experiments in the 19th century . But memory is not a monolith. It is one thing to remember how to drive a car, another to remember the events from your last birthday. This is yet different from recalling capital of France. There is a difference between the process that create a sense of familiarity for someone at a party and our ability to recall exactly who that person is and how we know them.
The old/new recognition test measures participants’ sense of familiarity for a list of items, some of which they’ve seen recently. It is of course possible that an item seems familiar, although it is actually new. By comparing how often participants claim to recognise a word to the number of correctly recognised words, we can estimate the reliability of an individual’s recognition memory. This task also yields a measure of recognition bias. Is a person more likely to falsely recognise a new word (false memory) or more likely to not recognise a previously shown one (poor recognition). This can help to understand the factors that improve or distort recognition, and how this differs for other types of memory.
Read on to learn how to run the old/new recognition test in Testable in minutes. You’ll also learn how to make sense of the result data that you’ll get from running the ONR test.

In this task, participants first progress through a series test learning trials where they only need to passively read a list of words that are show one by one for 1.5 seconds each and in a random order. In this (learn) phase, participants do not need to respond as the trials advance automatically.
After the list (in this example 50 words) has been shown, the second (test) phase begins. Here participants need to decide if they think they recognise the word from the learn phase. They do this using the ‘New’ and ‘Old’ buttons shown on screen. Here, 25 old and 25 new words are showed in a random order, so that either answer is equally likely.
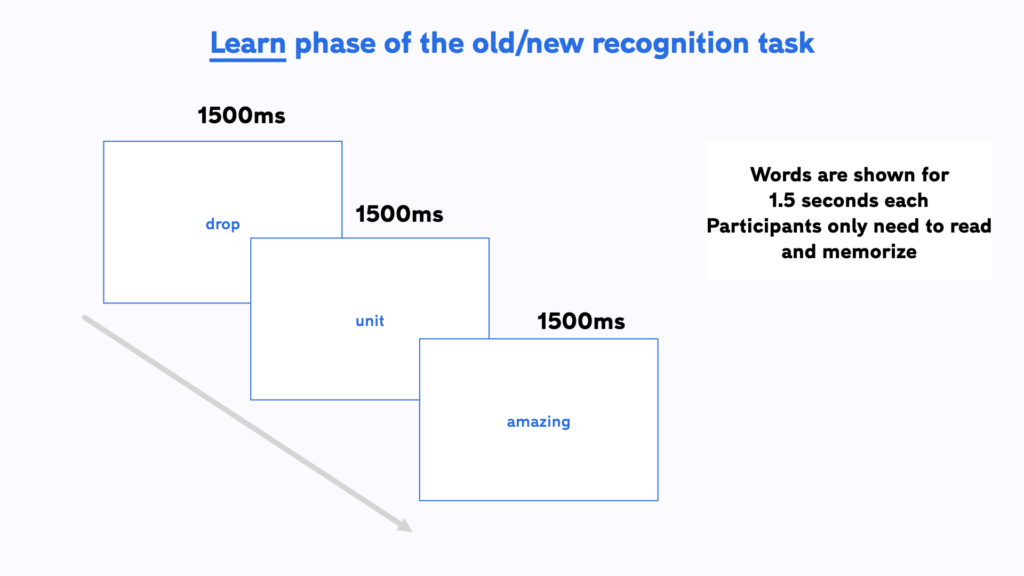
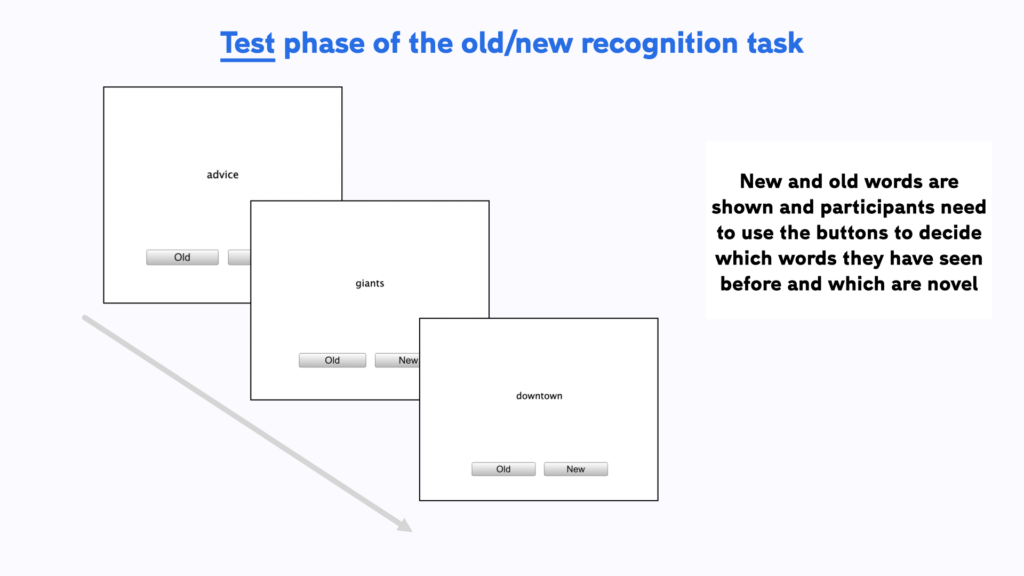
We have created a template for the ONR in Testable for you that you can access from our Library. It is set-up and ready to go and you can start collecting data straight away by sending the experiment link to your participant. Experiments in Testable will run in any standard browser. This makes it very easy to collect data both in the lab as well as online.
Experiments in Testable are fully customisable and you will not need to write a single line of code to edit them. The heart of each experiment is what we call the trial file. The trial file contains all information that Testable needs to run the experiment in a simple spreadsheet, that you can edit with any spreadsheet editor you like, such as Google Sheets or Excel.
To change any part of your experiment, you only need to change the values in the trial file.
Here are a few examples of changes you might want to make to the old/new recognition test:
Allow your participants to respond with the keyboard instead
If you prefer to allow you participants to respond using the keyboard instead of their mouse, you can easily change that in the trial file:
Change the task to an auditory old/new recognition test
In a 2010 paper Mulligan et al. were testing the effect of modality on recognition. In other words, how does recognition memory work differently for things we see (visual) compared to things we hear (auditory), contributing to the conversation about effective learning styles.
You can easily transform the template to become an auditory ONR test:
That’s it! All other parts of the projects can remain unchanged.
After importing this template to your library, you can collect data for your experiment by sharing the unique experiment link (i.e. tstbl.co/xxx-xxx) with your participants. Once participants complete the experiment, their results will appear in the ‘Results’ section of your experiment.
This experiment automatically measures the response time (RT column) and accuracy (correct column) of indicating whether the test word was old or new. For the analysis of this task we are interested in what participants responded in each trial (‘old’ or ‘new’) and if these responses were accurate or not. Here the first button (‘old’) is coded as ‘1’ and the second (‘new’) coded as ‘2’.
In the trial file we have also defined a column called condition1 that helps us keep track of which words are old and or new. This column has no bearing on the experiment logic, but helps us more easily analyse the results data. See the section below for more detail on how to compute a widely used statistic, the d’ score, for this experiment.
Once you have collected data from multiple participants, you can also use Testable’s ‘wide format’ feature, that automatically collates all individual result files into a single file where every participant’s data is represented as one ow in the data. This makes it easily compatible with statistical analysis packages like R or SPSS where you can assess the statistical significance of any differences you may find
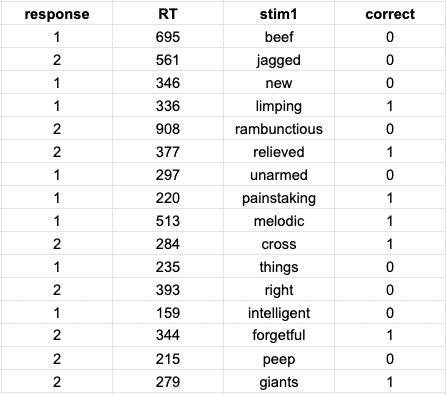
One way to score this task is to simply compute the mean of the correct column. This would give you get the proportion of words that were correctly identified as either old or new. However, in memory tasks there are other metrics that are more useful. This is because incorrectly rejecting a familiar word (not recognising) and incorrectly recognising a new word (false memory) are different kinds of errors that with different implications for someone’s memory performance.

One metric that encapsulates the ‘signal’ in a recognition test is the d’ (d-prime) score. The d’ score is often accompanied by a measure of bias C, which indicates if the participant was rather conservative or liberal with labelling words as ‘old’. Both scores together are a good summary of an individuals’ recognition memory performance. You can find a d’ prime calculator here and a tutorial on how to compute it by hand here.
As always, you can also use Testable’s ‘wide format’ feature to automatically collate all individual result files into a single file. In wide format results every participant’s data is represented as one row in the data. This makes it easily compatible with statistical analysis packages like R or SPSS where you can assess the statistical significance of any differences you may find.
Reference list:
Ebbinghaus H. Memory: a contribution to experimental psychology. Ann Neurosci. 2013;20(4):155-156. doi:10.5214/ans.0972.7531.200408
Standing, L. (1973). Learning 10000 pictures. Quarterly Journal of Experimental Psychology, 25(2), 207–222. doi:10.1080/14640747308400340
Mulligan, N. W., Besken, M., & Peterson, D. (2010). Remember-Know and source memory instructions can qualitatively change old-new recognition accuracy: The modality-match effect in recognition memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 36(2), 558–566. doi:10.1037/a0018408